By David Warren-Angelucci, OSS Channel Sales Manager
HPC hardware for AI Workflows on the Edge
The building blocks of an AI workflow are the same as any computational workflow:
While most AI workflows occur in the controlled environment of datacenters where servers have the HPC resources the applications need, many current AI applications require some or all the AI workflow steps to be performed out in the field, in harsh environmental conditions. Until now, companies with applications on the ‘edge’ have had to rely on low-performance hardware or deal with the latency of uploading data to the cloud; rugged edge-computing devices, like industrial PCs and IOT devices, are able to withstand the extreme environmental factors of harsh environments, but they do not come close to offering the same computational performance of servers in a datacenter. Because of this, AI applications on the ‘edge’ have had to compromise on performance, but not anymore!
With our latest line of “AI Transportable” products, One Stop Systems (OSS) supplies rugged appliances which have the same capacity of datacenter performance, but can be used for AI workflows in cars, planes, trucks, ships, drones, and any other environment which has never been able to support HPC hardware…until now. The products in the AI Transportable line are rugged, datacenter-type HPC products that are tailored for each of the four steps in the AI workflow. Companies with edge applications which require the highest performance compute power cannot compromise on performance; they need the components of the datacenter in the field.
With our “AI Transportable” product line, OSS brings the power of the datacenter to the edge!
OSS designs and manufactures high-performance computing systems that are uniquely positioned to support each stage of the AI Transportable workflow, and we have a range of products tailored to meeting the needs of each stage, based on the requirements of the application.
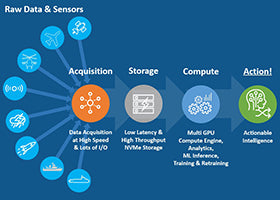
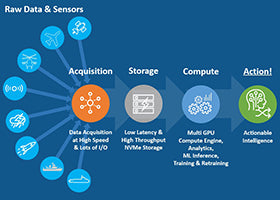
The 4 Stages of the AI Workflow
The ultimate goal of the AI workflow is to process raw data into actionable intelligence. OSS provides hardware platforms which expedite AI workflows and significantly reduce the time to take action.
The four fundamental building blocks of an AI workflow include: gathering raw data from sensors and other I/O devices (OSS has products which acquire significant amounts of data at high-speed), storing that data (OSS has products which support high-density storage in a small footprint), computing that data (OSS specializes in providing multi-GPU platforms for high-speed analytics, inference, AI training, and retraining), and then making intelligent decisions based on the knowledge gained from that data.








 It supports up to four double-wide add-in cards (like a GPU) and has 16 NVMe/SATA SSD bays in two removeable cannisters. The flexibility and utility of this all-in-one server are matched perfectly with its rugged nature for a wide variety of applications that may need more than only storage or only GPU computing.
It supports up to four double-wide add-in cards (like a GPU) and has 16 NVMe/SATA SSD bays in two removeable cannisters. The flexibility and utility of this all-in-one server are matched perfectly with its rugged nature for a wide variety of applications that may need more than only storage or only GPU computing. It may be overkill for many applications, but for those which require the highest performance storage and GPU computing at the edge, this dual-Rigel solution is unmatched.
It may be overkill for many applications, but for those which require the highest performance storage and GPU computing at the edge, this dual-Rigel solution is unmatched.The Future is Now
The push for supporting AI applications in the field is becoming increasingly evident. Companies are no longer able to accept the compromises that they must make by relying on the time-consuming latency of uploading data to the cloud so that it can be stored and computed in a datacenter before results are transferred back to the field, and traditional industrial box PCs are no longer able to support the intense storage & compute requirements of many AI workflows.
One Stop Systems is the solution -- leading the industry in offering rugged HPC solutions of varying scale for edge AI applications.
Click the buttons below to share this blog post!


Watching the conflicts play out recently in the Ukraine and Iran, it is certain that there has been not only massive adoption in implementation of AI, sensor processing, sensor fusion, and autonomy but also massive advancement of those technologies in relatively short time periods compared to any other time in history. The leaders on the battlefield are those that have harnessed and deployed these technologies without delay in alignment to standards, timing, or bureaucracy in acquiring. Because the level and pace of technology today is so steep, those who fail to adopt and move with a sense of urgency run the risk of falling behind in a technology battle from which they may never have the time or ability to catch up.


Before starting college in 2022, I had considered artificial intelligence (AI) a thing of the future, something I wouldn’t see until I was later in my years. With the birth of large language models (LLMs) like ChatGPT and the rise of machine learning systems, my world flipped on its head. Since joining the tech industry, I see I am not alone with this experience. From one year to the next, there is no telling what kind of technological developments we will bear witness to. When it comes to the defense and security of our nation, capitalizing on these advancements is paramount, lest we fall behind our adversaries. As a result, within the defense industry, marketers are required to become adaptable to the shifting needs of their company’s customers.
Get the latest news, product releases, upcoming events, blog posts and more!


{kind=link}