

By Athanasios Koutsouridis, Marketing Manager
At One Stop Systems Inc. (OSS), we are proud to offer high-performance solutions that help our clients tackle the most demanding computing workloads. That's why we are excited to talk about the NVIDIA H100 Tensor Core GPU, an incredibly powerful GPU designed to deliver exceptional performance for a wide range of use cases.
The H100 is built on the cutting-edge NVIDIA Hopper GPU architecture, making it an ideal choice for applications that require lightning-fast compute power. With fourth-generation Tensor Cores, the H100 delivers up to 5x faster AI training and 30x faster AI inference speedups on large language models compared to the previous A100 generation, making it one of the most advanced GPUs on the market, and a perfect match for our PCIe expansions and GPU servers.
In this blog post, OSS will delve into the H100's architecture and hierarchy, and explore some of the exciting use cases that this GPU is ideal for. Whether you are working with complex AI models, or require high-performance computing for scientific research, the H100 GPU is a game-changing solution that will help you achieve your goals faster and more efficiently than ever before.
The H100 GPU Hierarchy and Architecture
The rapid advancements in GPU compute architecture have brought about a significant evolution in NVIDIA's latest H100 GPU hierarchy. While the CUDA programming model has relied on grids and thread blocks to achieve program locality for years, the conventional thread block approach has become inadequate with the growing complexity of programs and the emergence of GPUs with over 100 streaming multiprocessors (SMs).
To tackle this issue, NVIDIA has introduced an innovative Thread Block Cluster architecture with the H100 GPU. This architecture provides a greater degree of control over locality, allowing for larger granularity than a single thread block on a single SM. With Thread Block Clusters, the CUDA programming model has expanded to a new level, adding threads, thread blocks, thread block clusters, and grids to the GPU's physical programming hierarchy.
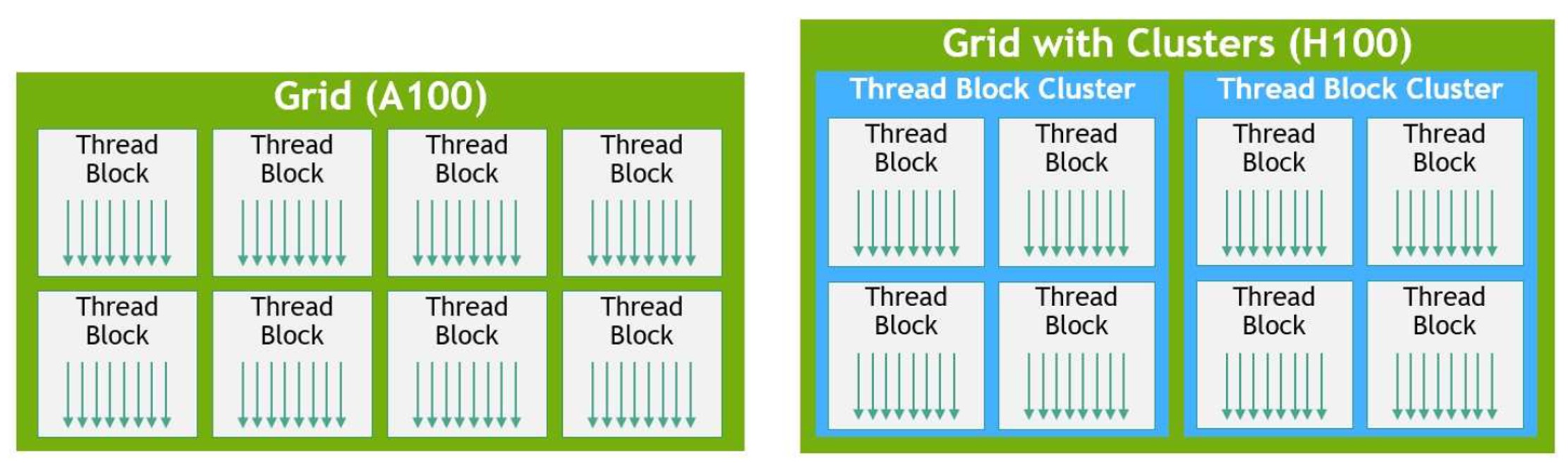
So, what exactly is a thread block cluster? Simply put, it is a collection of thread blocks that are scheduled concurrently onto a group of SMs. This new architecture aims to facilitate effective cooperation of threads across multiple SMs, leading to improved performance and execution efficiency.
The NVIDIA H100 GPU boasts numerous innovations, which makes it a powerhouse for OSS’ fields of AI Transportables and high-performance computing. Based on the new Hopper GPU architecture, the H100 is packed with cutting-edge features that make it more powerful, more efficient, and more programmable than any GPU that has come before it.
One of the most significant advancements in the H100 is its fourth-generation Tensor Cores, which perform matrix computations faster and more efficiently than ever before. This allows the H100 to handle a broader range of AI and HPC tasks with ease, making it an ideal choice for our clients who demand the best performance from their GPU.

The NVIDIA H100 is designed for high-performance computing workloads, and it is suitable for a wide range of use cases. Some of OSS’ most common client use cases for the H100 include:
Conclusion
At One Stop Systems Inc., we are constantly expanding our portfolio of high-performance GPU servers and PCIe expansions to provide our clients with the most advanced computing solutions available. We are proud to include the NVIDIA H100 in our line-up, as it represents a significant step forward in GPU technology.
The H100 is a high-end GPU that boasts numerous innovations, making it an ideal choice for our customers’ applications. With its advanced architecture and fourth-generation Tensor Cores, the H100 is one of the most powerful, programmable, and power-efficient GPUs to date, enabling users and applications to fully utilize all of their H100 GPUs' units at all times.
We believe that the H100 is an excellent choice for organizations that require high-performance computing capabilities. Its processing power and memory bandwidth make it ideal for handling the most demanding workloads, and its ability to deliver lightning-fast AI training and inference speedups on large language models make it a game-changing solution for organizations working with complex AI models.
Click the buttons below to share this blog post!


Watching the conflicts play out recently in the Ukraine and Iran, it is certain that there has been not only massive adoption in implementation of AI, sensor processing, sensor fusion, and autonomy but also massive advancement of those technologies in relatively short time periods compared to any other time in history. The leaders on the battlefield are those that have harnessed and deployed these technologies without delay in alignment to standards, timing, or bureaucracy in acquiring. Because the level and pace of technology today is so steep, those who fail to adopt and move with a sense of urgency run the risk of falling behind in a technology battle from which they may never have the time or ability to catch up.


Before starting college in 2022, I had considered artificial intelligence (AI) a thing of the future, something I wouldn’t see until I was later in my years. With the birth of large language models (LLMs) like ChatGPT and the rise of machine learning systems, my world flipped on its head. Since joining the tech industry, I see I am not alone with this experience. From one year to the next, there is no telling what kind of technological developments we will bear witness to. When it comes to the defense and security of our nation, capitalizing on these advancements is paramount, lest we fall behind our adversaries. As a result, within the defense industry, marketers are required to become adaptable to the shifting needs of their company’s customers.
Get the latest news, product releases, upcoming events, blog posts and more!


{kind=link}