
By Jaan Mannik, Director of Commercial Sales
Edge computing is becoming increasingly important due to the rapid growth of the Internet of Things (IoT), and the need for real-time data processing and analysis. Edge computing involves processing and storing data at the edge of the network, closer to where it is generated, rather than in a centralized location. Conducting these functions closer to where the action takes place means a decision can be made more quickly, producing reduced latency, improved security, greater reliability, and higher performance. This concept is becoming adopted by a wide range of market verticals today, however, edge locations are difficult to optimize and often require reduced physical footprints, non-traditional power & cooling envelopes, and unique rugged design concepts. Enterprise applications requiring the highest end compute for their AI workloads at the Edge are leveraging data-center grade NVIDIA GPUs to get even greater performance. In this blog, I’ll be covering the workhorse advancing HPC at the edge, and how it is being deployed in the real-world AI Transportable applications of today.
 The workhorse advancing HPC at the Edge is the GPU (graphics processing unit), by providing a powerful and efficient way to process large amounts of data in real-time. Using GPUs for parallel computing operations is not a new concept. Supercomputers started using GPUs in traditional rack-scale environments back in 2005, when Oak Ridge National Laboratory's Jaguar supercomputer became the first to incorporate GPUs for scientific computing, specifically using GPUs from NVIDIA. The use of GPUs in supercomputers increased in popularity in the following years, due to their ability to perform massive amounts of parallel processing, making them a perfect candidate for high-performance computing applications, such as simulations and modeling, because they can perform many operations simultaneously. As of June 2021, seven of the top ten world's fastest supercomputers use GPUs to accelerate their computations, including the top ranked Fugaku in Japan.
The workhorse advancing HPC at the Edge is the GPU (graphics processing unit), by providing a powerful and efficient way to process large amounts of data in real-time. Using GPUs for parallel computing operations is not a new concept. Supercomputers started using GPUs in traditional rack-scale environments back in 2005, when Oak Ridge National Laboratory's Jaguar supercomputer became the first to incorporate GPUs for scientific computing, specifically using GPUs from NVIDIA. The use of GPUs in supercomputers increased in popularity in the following years, due to their ability to perform massive amounts of parallel processing, making them a perfect candidate for high-performance computing applications, such as simulations and modeling, because they can perform many operations simultaneously. As of June 2021, seven of the top ten world's fastest supercomputers use GPUs to accelerate their computations, including the top ranked Fugaku in Japan.
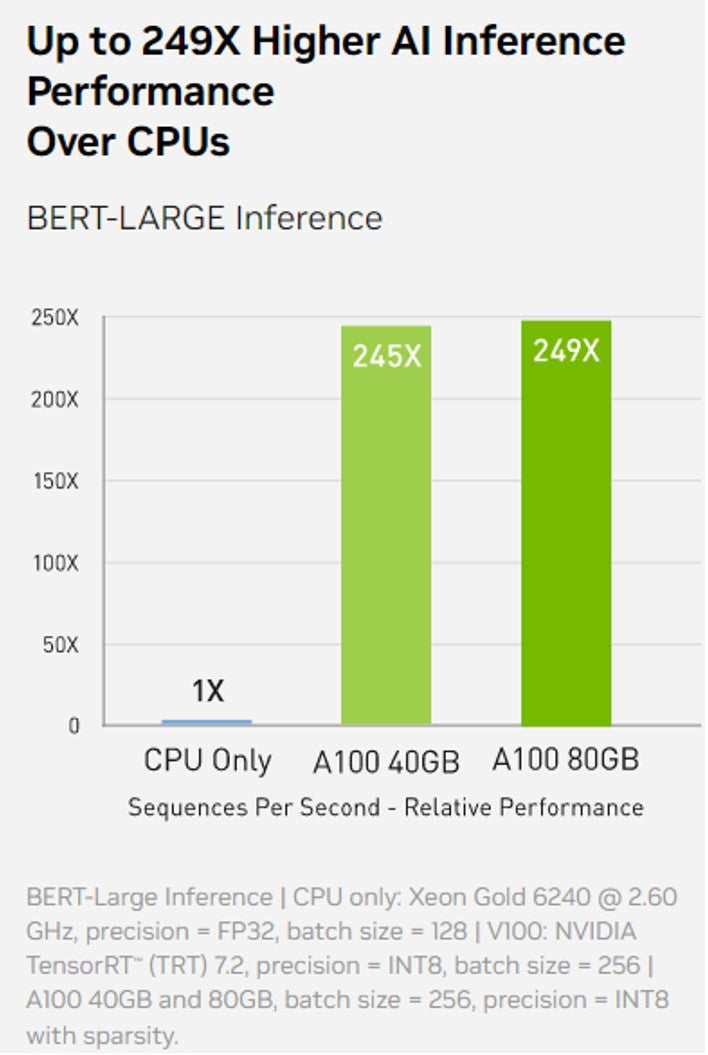
So why is the GPU advancing HPC at the Edge? A single NVIDIA A100 80GB GPU can greatly increase the performance, compared to a CPU, and requires a much smaller footprint. As NVIDIA explains “On state-of-the-art conversational AI models like BERT, A100 accelerates inference throughput up to 249x over CPU.” This makes GPUs ideal for high-performance computing at the Edge, where fast processing is essential to ensure timely decision-making and response. A single 3U rugged server supporting 4 NVIDIA A100 GPUs can replace an entire rack of CPU-based servers traditionally found clustered in a datacenter, which is a game changer for Edge applications where size, space, power, and cooling are problematic. For example, in autonomous vehicles, GPUs can process sensor data and make real-time decisions to control the vehicle. In agriculture, GPUs can identify weeds to eradicate to help crops grow without using pesticides. In healthcare, GPUs can analyze medical images in real-time to provide more accurate diagnoses. One Stop Systems 3U SDS A100 GPU Server is an NVIDIA Certified rugged HPC platform being deployed in these environments today, supporting up to four A100 GPUs and 500TB of NVMe flash storage, in a 3U compact chassis, optimized for the very edge.

Overall, edge computing can help organizations improve their operational efficiency, reduce costs, and improve the performance and reliability of their applications. Adding enterprise-class GPUs brings the power of the data center to the very Edge, by providing a powerful and efficient way to process large amounts of data in real-time where it is most needed. This ‘workhorse’ is an incredibly important technology that is pushing the limits of Edge computing, enabling new and innovative applications that were not possible before.
Click the buttons below to share this blog post!
Share:
What can an NVIDIA H100 GPU do?
Saving the Warfighter with AI